モデル
モデルテキストから画像へ#01
ナノバナナ
Googleの最新画像編集モデルGemini 2.5
画像生成からビデオ作成、音声合成から音楽作曲まで、私たちの包括的なAI作成ツールコレクションを探索してください。必要なものはすべてここにあります。
オールインワンAIツール
Googleの最新画像編集モデルGemini 2.5
イデオグラム V3 ターボは、イデオグラム 3.0 テキストから画像へのモデルの中で最も高速かつコスト効率の高いバリアントです。
Imagen-4 Fastは、GoogleのImagen-4ファミリーの速度最適化バージョンです。画像の忠実度、細部、タイポグラフィの多くの改善を維持しながら、超高精細な洗練さの一部を犠牲にして、より速い生成と低コストを実現しています。大量生産や迅速な反復に最適です。
Qwen-Imageは、アリババのQwenチームによるオープンソースの画像基盤モデルで、約200億のパラメータを持ち、MMDiT(マルチモーダル拡散トランスフォーマー)アーキテクチャを基に構築されています。複雑なテキストレンダリング(中国語/英語の混在、複数行/複数段落のテキストを含む)や正確な画像編集において大きな進歩を遂げており、多様な視覚コンテンツの生成と編集の両方をサポートします。
FLUX 1.1 Proは、Black Forest Labsのフラッグシップテキストから画像へのモデルです。FLUX 1.0 Proからの大幅なアップグレードであり、約120億のパラメータ、マルチモーダルと並列拡散トランスフォーマーブロックのハイブリッドアーキテクチャ、そして速度と画像品質を向上させるためのフローマッチングによるトレーニングを組み合わせています。FLUX 1.1 Proは、Artificial Analysisイメージアリーナなどのベンチマークで最先端の結果を達成し、強力なプロンプトの忠実性、視覚的詳細、出力の多様性を維持しながら、はるかに高速な生成を提供します。
Imagen-4 Ultraは、GoogleのImagenファミリーのフラッグシップモデルで、最大限のリアリズムと画像品質を求める方に向けて設計されています。強化されたライティング、テクスチャ、プロンプトの忠実度、テキストレンダリングを備え、複数のアスペクト比で高解像度出力をサポートします。広告、出版、ブランドイメージなどの高級ビジュアルコンテンツに最適です。Googleのimagen-4.0-ultra-generate-001モデルに対応しています。
Ideogram-V3-クオリティは、Ideogram 3.0ファミリーの中で最高品質のランクです。TurboやBalancedバージョンと比較して、速度を犠牲にしても、優れた画像の忠実度、強力なプロンプトの整合性、より詳細な照明、素材、テクスチャ、そして優れたタイポグラフィ/テキストレンダリングを提供します。
Ideogram-V3-バランスは、Ideogram 3.0 ラインナップの中間層で、画像品質、生成速度、コストのバランスを取るように設計されています。Turbo層よりも高品質でありながら、Quality層よりも高速で手頃な価格で、“十分な”美学を求めるユースケースに最適です。
FLUX.1 Kontext [pro]は、Black Forest Labsのコンテクストモデルファミリーの中でハイエンドなバリアントです。マルチモーダル入力(テキスト+参照画像)をサポートし、テキストから画像の生成や、自然言語の指示に基づく既存画像の編集が可能です。迅速で反復的なワークフローのために設計されており、編集を通じてキャラクター/オブジェクト/スタイルの一貫性を重視します。多くの既存の最先端モデルよりも大幅に高速な推論速度を実現しており、高品質で複数回の修正を求めるクリエイターに最適です。
ルシッド・オリジンは、Leonardo.AIによって最近リリースされたモデルで、優れた視覚品質、スタイルの多様性、プロンプトの忠実性を提供するよう設計されています。デフォルトでフルHD画像を生成し、より豊かな鮮やかさ、優れた色の深み、キャラクター、文化、視覚的視点の多様性を向上させています。また、テキスト、レイアウト、グラフィックデザイン要素も巧みに扱います。安定した出力品質とスタイルの柔軟性のバランスを求めるユーザーに最適です。
Hidream-L1-Fastは、オープンソースのHiDream-L1モデルを基にしたprunaAIの最適化された「高速」バリアントです。pruna AIの最適化ツールキットを使用し、基礎モデルの視覚的忠実性とプロンプト応答性を維持しながら、非常に低い遅延と低コストでの画像生成を実現します。
イデオグラム-V2A-ターボは、イデオグラムV2/V2Aファミリーのターボ(速度最適化)バリアントです。生成速度を向上させ、コストを削減しながら、優れた画像品質、テキストレンダリング、プロンプトの忠実性を維持します。高い忠実度を必要とせずに、迅速なビジュアル出力、頻繁な反復、またはバッチ画像生成を望むユーザーを対象としています。
FLUX.1 Kontext [max]は、Black Forest LabsによるFLUX.1 Kontextファミリーの最上位モデルで、「高速での最大パフォーマンス」を謳っています。プロンプトの遵守性が大幅に向上し、タイポグラフィ生成が改善され、編集の一貫性が非常に高く保たれています。高い推論速度を維持しながら、マルチモーダル入力(テキスト+参照画像)、ローカル編集、スタイル参照、複数の編集ターンにわたる反復的な洗練をサポートします。画像の品質、詳細、コントロールに高い要求があるユースケース、例えばブランディング、広告、企業デザインに最適です。
Google Imagen-4は、DeepMind/GoogleによるImagenファミリーの最新バージョンであり、テキストから画像への生成における大きな進歩を表しています。以前のバージョンに比べて、画像の忠実度、照明/詳細/質感のリアリズム、テキスト/タイポグラフィの可読性が向上しています。約2Kの解像度出力をサポートし、標準のImagen-4、「Fast」バリアント、「Ultra」高品質バリアントなど、複数のバリエーションが用意されており、ユーザーは速度、コスト、視覚品質の間でトレードオフを行うことができます。利用ケースには、クリエイティブデザイン、マーケティング/広告、出版、ブランドビジュアルなどがあります。
FLUX.1 プロ ウルトラは、Black Forest LabsのFLUX.1 プロ ラインの高級バリアント(「ウルトラモード」)で、追加のローモードを備えています。このモデルは、標準のFLUX.1 プロを拡張して高解像度(最大約4メガピクセル)をサポートしながら、比較的高速な推論(画像あたり約10秒)を維持します。ウルトラモードは構図の精度とプロンプトの遵守を強調し、ローモードはより自然な質感、照明、リアリズムを重視します。商業的なビジュアルデザイン、広告、コンセプトアート、高精細でプレミアムな出力が求められる用途に最適です。
Recraft V3は、デザイナーやクリエイティブプロフェッショナルのためにRecraft AIがゼロから開発したテキストから画像への変換モデルです。ベンチマークでトップクラスのモデルにランクインしており、しばしばMidjourneyやOpenAIなどを凌駕する画像品質を誇ります。その特徴は、グラフィックデザインにおける制御機能の強力なサポートにあります。具体的には、正確なテキスト配置/レイアウト、ベクターグラフィックスの出力、ブランドスタイルの一貫性、長いテキストプロンプトの処理などです。デザイン志向のアイデアを忠実かつ制御可能な形で製品化可能なグラフィックに変換することを目指しています。
Recraft V3 SVG(コードネーム: red_panda)は、ロゴタイプやアイコンを含む高品質なSVG画像を生成できるテキストから画像へのモデルです。このモデルは幅広いスタイルをサポートしています。
ControlNet-Scribble(jagilleyによる)は、Stable Diffusion + ControlNetフレームワークを基にした「スケッチ/落書きガイド」画像生成モデルです。ユーザーは粗い線画や落書きを提供(またはアップロード)し、テキストプロンプトと共にモデルに入力します。モデルはスケッチを使って構造(レイアウト/形状/全体の構成)をガイドし、テキストプロンプトがスタイル、内容、詳細を決定します。簡単なスケッチでもうまく機能し、アーティストでない人でも詳細で視覚的に魅力的な画像を生成できます。このモデルは中程度のコストで、良好な推論時間を持っています。
これは、Stability AI の特定バージョンの Stable Diffusion です。一般的なテキストから画像へのディフュージョンモデルで、解像度、プロンプトとネガティブプロンプト、推論ステップ数、ガイダンススケールなどの設定が可能です。デフォルトの画像サイズは 768×768(または 64 の倍数の他の寸法)です。イラスト、コンセプトアート、クリエイティブアートなど、幅広いビジュアル生成タスクに適しています。
fofr/sdxl-emojiは、ユーザーfofrによってLoRA/テキスト反転を使用して微調整されたStable Diffusion XL(SDXL)のバージョンで、Appleの絵文字スタイルの画像を生成するように訓練されています。Dreambooth LoRAとテキスト反転を活用して、特別なトリガートークン(例:<s0><s1>)を定義し、この絵文字スタイルの生成を切り替えます。ライセンス:CreativeML-OpenRAIL-M。絵文字アイコンスタイルやカートゥーン風の視覚表現が必要なときに便利です。
Segmindのステーブル・ディフュージョン・モデル (SSD-1B) は、SDXLの50%小型化されたバージョンで、60%の速度向上を実現しながら、高品質なテキストから画像生成能力を維持します。
AIでステッカーを作成。透明な背景のグラフィックを生成します。
ルーマ フォトンは、ルーマラボが開発した次世代のテキストから画像への生成モデルです。画像の忠実度、詳細、プロンプトの理解において大幅な改善を提供しながら、コスト効率も維持しています。フォトンには、速度と低コストを重視した「フラッシュ」バリアントもあります。フォトンは、高品質な出力を求めつつ、コストや時間の管理が必要なクリエイター、デザイナー、ビジュアルコンテンツ制作者を対象としています。
v1.5モデルを使用してタイル可能な出力を生成するためのStable Diffusionフォーク
AIによるアート生成の未来を体験してください。 ステーブルイメージウルトラは、最高の精度、色の忠実度、芸術的構造を求めるクリエイターのために設計された、最も先進的なテキストから画像への生成サービスです。 ステーブルディフュージョン3.5を基に、次世代のトレーニング技術で強化されたウルトラは、プロンプトの理解、鮮明なタイポグラフィ、複雑な構図、動的なライティングにおいて卓越した性能を発揮し、視覚的に一貫性のある、フォトリアリスティックまたはスタイライズされたアートを人間が作ったかのように生成します。
驚くほど美しいAI画像を瞬時に生成—プロンプトエンジニアリングは不要です。 ステーブルイメージコアは、スピードと品質の両方に最適化された、当社の主要なテキストから画像生成サービスです。スタイル、シーン、キャラクターを問わず、美しく一貫性のある画像を数秒で提供します。 コアは、効率性と一貫性を重視するプロフェッショナルからカジュアルなクリエイターまで、すべての人にとってAI画像作成を簡単にします。
Stability AIの最先端の拡散モデルを発見しましょう。 Stable Diffusion 3.5は、比類のない画像品質、プロンプトの正確性、そして複数のモデル層(LargeからFlashまで)にわたる生成速度を実現しています。 クリエイター、アーティスト、開発者のために設計されたSD 3.5は、細やかな制御、創造的な柔軟性、そして最先端のパフォーマンスでプロフェッショナルな結果を提供します。
AIによるアート生成の未来を体験してください。 Stable Image Ultraは、最高レベルの精度、色の忠実度、芸術的な構造を求めるクリエイターのために設計された、最も高度なテキストからイメージ生成サービスです。 Stable Diffusion 3.5を基盤にし、次世代のトレーニング技術で強化されたUltraは、プロンプトの優れた理解、鮮明なタイポグラフィ、複雑な構図、ダイナミックなライティングを提供し、視覚的に統一された、フォトリアリスティックまたはスタイライズされたアートを人間が作り出したかのように生成します。

Nano Bananaは、次世代の画像生成と編集モデルで、テキストプロンプトと画像入力を組み合わせて、驚異的な忠実度でビジュアルを作成または変換します。マルチイメージ融合、キャラクターの一貫性、ターゲット編集、アウトペインティング、インペインティングをサポートし、すべて自然言語コマンドで駆動されます。Geminiエコシステムを通じて展開され、クリエイター、ブランド、開発者向けにプロフェッショナルな画像ワークフローを提供します。

ジェミニ 3 プロ イメージは、プロフェッショナル品質のAI画像生成と編集を提供します。1K/2K/4Kの解像度、鮮明なテキストレンダリング、リアルタイムデータの統合、最大14枚の参照画像のサポートにより、マーケティング素材、インフォグラフィックス、コンセプトアート、UI/UXモックアップなどに最適です。
Seedream 4.0は、バイトダンスが提供する次世代のマルチモーダル画像モデルで、画像生成と画像編集を統合したアーキテクチャを持っています。高解像度(最大4K)、複数の参照画像、自然言語による正確な編集、そして高速な推論速度をサポートしており、デザイナー、クリエイター、商業画像アプリケーションに最適です。
FLUX.1 [schnell](ドイツ語で「速い」)は、Black Forest Labsによるテキストから画像への生成モデルです。これはFLUX.1ファミリーの速度最適化/蒸留版です。約120億のパラメータ(12B)を持ち、修正されたフロートランスフォーマーアーキテクチャを使用し、潜在敵対的拡散蒸留を通じてトレーニングされており、非常に少ない推論ステップ(1〜4ステップ)で高品質の画像を生成できます。Apache-2.0ライセンスの下でリリースされており、個人、科学、商業利用が可能です。
Seedream 3.0は、ByteDanceによる中国語と英語のバイリンガルのテキストから画像への基盤モデルです。Seedream 2.0を基に、ネイティブ2K解像度の出力(アップスケーリングなし)、高速な推論、より良いプロンプトの理解と整合性、特にテキスト/看板/レイアウトのシナリオでの優れたパフォーマンスを向上させています。スピードと視覚品質の両方を必要とするユーザー、特に中国語/英語のプロンプトを混在させるユーザーに適しています。
フォトン・フラッシュは、Luma Labsによるフォトンファミリーの高速/“フラッシュ”バリアントです。高い忠実度、プロンプトの遵守、創造的な柔軟性を維持しながら、コストと遅延を大幅に削減することを目指しています。テキストから画像への生成、画像/スタイルの参照、キャラクターの一貫性をサポートします。
FLUX.1-devは、Black Forest LabsのFLUX.1モデルファミリーの「Dev」(開発者)バージョンで、PrunaAIによって最適化されています。圧縮、量子化、コンパイラ最適化などの技術を適用し、速度と効率を向上させつつ、画像品質とプロンプトの忠実性を維持することを目指しています。APIまたはローカルで使用可能で、低コスト/低遅延で合理的に高い視覚結果を求めるユーザー向けです。良好なハードウェア条件下では、推論は非常に高速です。
SANA-Sprint-1.6Bは、NVIDIA Labs(Sanaファミリー)による超効率的なテキストから画像へのモデルで、約16億のパラメータを持っています。連続時間一貫性蒸留(sCM)と潜在敵対的拡散蒸留(LADD)を組み合わせたハイブリッド蒸留戦略を使用しており、非常に少ない推論ステップ(1~4ステップ)で高品質な画像生成を可能にします。スピードと品質のバランスが優れており、リアルタイムの視覚タスクやインタラクティブな生成に最適です。
Minimax イメージ-01 は、MiniMax(Hailuo AI)によるテキストから画像への生成モデルで、人を対象とした参照画像の使用をサポートしています。プロンプトから画像への高い忠実性、豊かな光と影、環境の詳細、人や物の自然なレンダリングを重視しています。リアルなスタイルと人やシーンの詳細を求めるアプリケーションに適しています。
リアリスティックビジョン v5.1(lucataco / SG_161222)は、Stable Diffusion 1.5を基にしたリアリスティックビジョンファミリーの高品質バージョンです。非常にリアルで詳細な画像を目指して設計されており、アーティファクトを減らすためにVAEと併用することで最適に機能します。特にポートレート、環境照明、肌のような質感、自然の風景に優れています。製品ビジュアル、広告、ポートレート作品、風景レンダリングなど、写真のようなリアリズムが求められるタスクに最適です。
LAION HighResで学習し、内部データセットで微調整されたtext2imgモデル
多言語対応のテキストから画像への潜在拡散モデル

Imagen 4.0はGoogleの次世代テキストから画像へのモデルラインアップで、3つのバリアントを提供します: • imagen-4.0-generate-001: 標準の高品質生成モード。 • imagen-4.0-fast-generate-001: 忠実度を大きく損なうことなく速度に最適化された高速バリアント。 • imagen-4.0-ultra-generate-001: 最高の視覚的詳細と解像度を提供する超高精細バリアント。

どんな画像も鮮やかなミニチュアに変換。Google Nano Bananaの力で、数分で驚くほどスタイリッシュなキャラクターモデルを作成します。

最先端のAI彫刻ジェネレーターを活用して、見事でユニークな芸術作品を作り上げ、デジタルデザインでクリエイティブなプロジェクトを手軽に向上させましょう。

AI猫画像ジェネレーターを使えば、いつでもどこでもリアルな猫を生成できます。プロンプトは不要で、写真だけでOKです。

Nano BiBiのファッションマガジンで、あなたの写真を雑誌の表紙にふさわしいハイファッションな編集ルックに変身させましょう。Google Nano Bananaが提供するこのAIマガジンカバー生成ツールは、Vogueスタイルのグラマーショットやランウェイ風のモデル写真、エディトリアルポートレートを作成し、真のファッションフォワードな体験を提供します。

単一の写真から9グリッドのフォトブースレイアウトを作成します。セルフィーやポートレートをアップロードして、Nano Banana AIでリアルなフォトブースグリッドを瞬時に生成します。

AIポーズ転送技術で写真を変換します。被写体と参照ポーズ(モデル、絵、スティックフィギュア)となる2枚の画像をアップロードしてください。プロンプトは不要で、無料で使用できます。

あらゆる画像を鮮やかなアクションフィギュアに変換し、驚くほどスタイリッシュなキャラクターモデルを数分で簡単に作成できます。Google Nano Bananaが提供します。

Nano Banana AIで建物の写真をかわいい3Dモデルに変換 - 自動建築検出、3D生成&プロフェッショナルなモデリング。

ナノバナナAIで古い写真を修復 - 高画質修復、損傷修復、自然な色付け。無料のAI写真修復ツールで思い出を瞬時に蘇らせましょう!

ユニークな刺繍パターンを自動で無料生成。プロのようにデザインできる最高のAIツールで、時間を節約しインスピレーションを刺激します。

Nano BiBi 80年代フィルターで黄金の80年代未来を体験!リアルでインスピレーションを与える、安全な変身をオンラインでお楽しみください — ダウンロードやサインアップは不要です。

Nano BiBi AI服装チェンジャーで服をバーチャルに試着しましょう。服装をアップロードし、アバターを選択して、リアルにどのように見えるかを確認できます。

AI絵文字ジェネレーターでアイデアを絵文字に変換。お気に入りのSlackやDiscordの絵文字をワンクリックで作成できます。

あなたの写真をコレクション可能な3Dキャラクターフィギュアに変身させ、パッケージ付きでお届けします。

人物をファンコポップフィギュアに変身させ、パッケージの中とその横に表示します。

あなたのテーマを抱きしめたくなるような柔らかいぬいぐるみに変身させます。Nano BiBiによって動力を得て、Google Nano Bananaで生成されます。
Nano BiBiのポーズリファレンスを使えば、ある画像のポーズを別のキャラクターに適用できます。Google Nano Bananaの技術を活用したこのAIポーズ転送ツールは、キャラクターポージングやアクションポーズの生成、創造的な構図のマッチングに最適です。アーティスト、コスプレイヤー、イラストレーターにぴったりです。

Nano BiBiのフォトリアリスティックへを使用して、あなたの絵やイラストを驚くほどリアルな写真に変換しましょう。Google Nano Bananaによって強化されたこのAI画像コンバーターは、スケッチ、アニメ、デジタルアートを超リアルな写真品質に変えます。リアルな結果を求めるアーティスト、デザイナー、クリエイターに最適です。

Nano BiBiのアーキテクチャモデルを使用して、どんな建物も詳細なミニチュア建築モデルに変換します。Google Nano Bananaによって強化されたこのAI建築ツールは、リアルなスケールモデル、3Dビジュアライゼーション、現実的な建築レンダリングを作成します。建築家、デザイナー、ホビーストに最適です。

Google Nano Bananaが提供するNano BiBiのメイクアップ分析で、あなたのポートレートのメイクを分析します。このAI美容ツールは、ファンデーション、アイライナー、口紅、全体のスタイリングをレビューし、赤ペンで改善点を提案します。これにより、化粧の細部を洗練し、新しいルックを探求し、完璧な結果を達成する手助けをします。

Nano BiBiのペインティングプロセスで、あなたのアートが命を吹き込まれる様子を視覚化しましょう。Google Nano Bananaが提供するこのAIツールは、ラフスケッチから完成した絵画までの4ステップグリッドを生成します。アーティスト、学習者、クリエイティブなショーケースに最適です。

Nano BiBiの線画描画を使って、写真をクリーンな線画に変換しましょう。Google Nano Bananaによって強化されたこのAIスケッチツールは、画像を必要なアウトラインに削減し、ミニマリストなドローイング、デジタルインキング効果、イラストレーションに適したスケッチを作成します。アーティスト、デザイナー、クリエイティブプロジェクトに最適です。

クリーンな線画を厳密なパレット制御で完全に色付けされたイラストに変換します。ナノバナナAIモデルは、選択した参照画像から主要色、二次色、アクセントカラーを自動的に抽出し、それらを肌、髪、服、背景に論理的に適用します。

Nano Bibiプラットフォーム上でNano Bananaモデルを使用して、フォトリアリスティックでスタイリッシュな画像を作成します。このワークフローは、正確な顔の一貫性、自然な照明効果、柔軟なスタイルコントロールを保証し、ポートレート、コスプレ写真、クリエイティブなシーン生成に最適です。

AIステッカー生成器を使って、あなたの顔やキャラクターをかわいくて萌えなアニメ風ステッカーに変換しましょう。WhatsApp、Telegram、Discord、iMessageにぴったりのかわいいアウトラインと鮮やかな色彩です。

太いアウトライン、明るい色、ハーフトーンパターンを使ってポップアートスタイルのAIステッカーを作成します。あなたの顔を劇的でヴィンテージなコミックステッカーパックにカスタマイズして、ソーシャルアプリやチャットで使用しましょう。

プロフィール写真をクレイメーション風のAIステッカーに変身させましょう。手作りの粘土のような質感と誇張された表情で、WhatsAppやTelegramのステッカーパックに最適です。

カラフルなレトロピクセルアートスタイルでAIステッカーを生成します。8ビットやグリッチの美学を愛するゲーマーやコレクターに最適で、WhatsApp、Discord、Telegram用にエクスポート可能です。

レイヤー状でグラフィティ風のデザインを持つステッカーボムスタイルのAIステッカーを作成します。あなたの写真がステッカーの爆発の中心で漫画キャラクターになり、どのチャットアプリでもシェア可能です。

AIステッカーカードでレトロなサッカーのノスタルジアを再現。サッカーファンがカスタムWhatsAppやTelegramステッカーパックを作成するのに最適です。

AIを使って、1960年代の美学を持つレトロなボリウッド風ステッカーを生成します。クラシックなインド映画の魅力を捉え、WhatsAppやTelegram用のカスタムステッカーパックとしてエクスポートします。

日本のレトロなマッチ箱アートスタイルでAIステッカーを生成します。限られたカラーパレット、風合いのあるテクスチャー、キッチュなイラストが特徴です。ヴィンテージとユーモラスなステッカーデザインの完璧な融合です。

ユニコーンや虹、魔法の要素とともに、あなたを王族、王様、女王様、王子様、またはプリンセスに変えるAIステッカーを作成します。遊び心あるカスタムステッカーパックに最適です。

古い写真を高解像度の1080×1920画像に修復して、新しい命を吹き込みましょう。色を強調し、明瞭さを向上させ、現代の写真美学でスタイリッシュで本格的な外観を実現します。

どんな画像も鮮やかなミニチュアに変換。Google Nano Bananaの力で、驚くほどスタイリッシュなキャラクターモデルを数分で作成します。

アニメキャラクターをコスプレコンベンションの写真に変換します。任意のアニメキャラクターをアップロードして、Nano Banana AIでリアルなコスプレコンベンションシーンを即座に生成します。

白黒写真を数秒でカラーに変換。面倒な手続きなしで無料のAIカラー化を体験してください。登録不要です。

GoogleマップをAIで実世界のシーンに変換 - 自動方向検出、シーン生成、位置の視覚化。無料ツールで地図の方向を瞬時に実現!

GTAポートレートジェネレーター。あなたの写真を瞬時に本格的なグランド・セフト・オートのキャラクターに変身させます—ソーシャルメディアやプロフィール写真に最適です。

Nano Banana Geminiのために作られた、かわいくてミニマルな動物デザインの素敵なコレクションです。シンプルでありながら魅力的なイラストは、遊び心のある形、丸みのあるフォルム、温かみのある表情を強調しています。ステッカー、塗り絵、子供向けの本、または居心地の良いデザインプロジェクトに最適です。

キュートステッカーイラストジェネレーターは、商業的な魅力を持つ高品質で愛らしいステッカー風イラストを生成するために設計されたAI搭載の画像作成ツールです。エッフェル塔、万里の長城、自由の女神、シドニーオペラハウスなど、世界的に有名なランドマークと一緒に、文化的またはテーマに沿った衣装を着た魅力的な動物キャラクターを作成することを専門としています。 このツールは、かわいいキャラクターデザイン、柔らかいアウトライン、明るいカラーパレット、そしてクリーンな白い境界線に焦点を当て、光沢のある印刷対応のステッカーアートワークを提供します。ステッカー商品化、デジタルステッカー、オンデマンド印刷製品、ブランディング資産、ソーシャルメディアビジュアルに最適です。各イラストは中心に配置され、表現力豊かで、明瞭さを追求しており、デジタルおよび物理的な配布の両方に適しています。 コレクタブルステッカー、旅行をテーマにしたキャラクターアート、教育用ビジュアル、遊び心のあるブランドマスコットを作成する場合でも、このAIモデルは、デザインスキルを必要とせず、一貫した高詳細のステッカーイラストを、楽しく表現力豊かなスタイルで提供します。

私の写真を[ピクサーアニメーション]スタイルの[3D漫画]アバターに変換し、顔の特徴と表情を維持した高品質のデジタルアート

実際の写真を楽しい漫画風イラストに変換し、元のキャラクターの個性を保ちます。

ペットの写真を調整して、閉じた目を自然に開いたように見せ、表情を柔らかくリアルに保ちます。

ランドマークを強調し、画像に情報注釈を直接重ねる拡張現実スタイルの体験を生成します。

画像内の特定のオブジェクトにカスタムテキストを挿入し、表面や視点に自然に合わせます。

製品を人の手やシーンに挿入し、マーケティングやプレゼンテーションのためのリアルな製品配置ビジュアルを作成します。

被写体をプロフェッショナルな環境に配置し、適切なビジネスアタイアでポートレートを変身させます。

リラックスしたデニムの装いで、日常的なカジュアルファッションを演出しましょう。
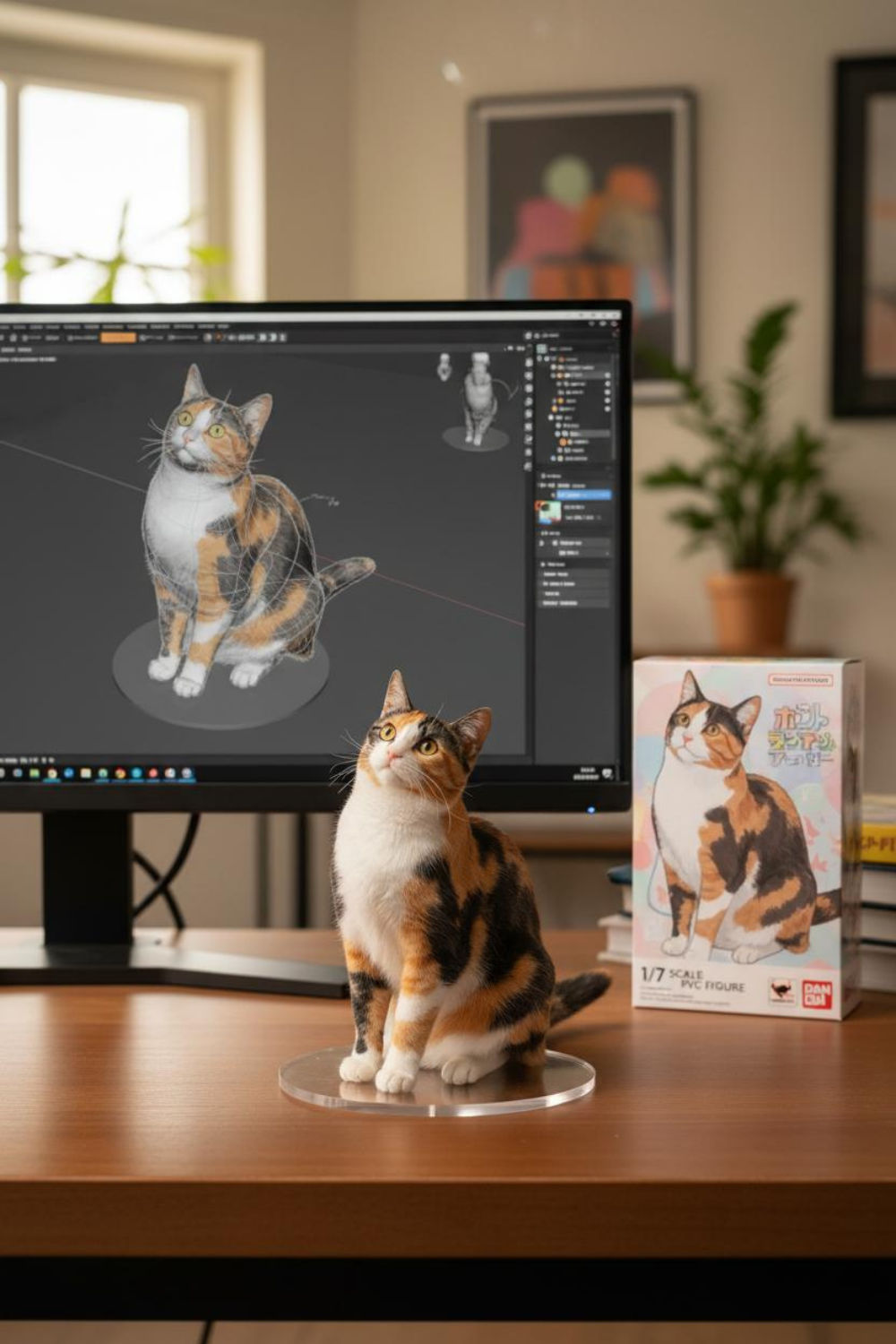
現代的なワークスペースで、デジタル彫刻プロセスとブランド包装を強調し、非常にリアルなPVCフィギュアをプロフェッショナルに展示します。

画像の元の内容と視覚品質を保ちながら、目に見える透かしを除去します。

画像の背景を象徴的なランドマークを特徴とする風光明媚な海辺の遊歩道に変更し、自然な被写界深度を維持します。

楽しいバナナテーマのジュエリーを追加して、ポートレートを遊び心があり目を引くルックにします。

古い写真を現代風に蘇らせるために、損傷を修復し自然な色を追加します。

芸術的な物語を伝えるために、正確な姿勢の参照に従って、都市のスカイラインの上でキャラクターがバイオリンを演奏するポーズで交流する、ドラマチックで象徴的なシーンを作成します。

お祝いにぴったりな、カメラ目線でおしゃれなアクセサリーを身につけたかわいい犬の誕生日ポートレートを生成します。

服をモデルに着せた状態を、画像を重ね合わせてバーチャルにプレビューします。

友達が集まり、笑い合う活気ある海辺の集いを、共通のオブジェクトに焦点を当てて構成します。
コレクターやデザイナー向けに、詳細なPVCモデル、デジタル彫刻ソフトウェア、ブランドパッケージを備えたプロフェッショナルなフィギュアディスプレイシーンを作成します。

キャラクターをセルフィー風の視点で実際の旅行先に配置し、雰囲気や表情をそのままに保ちます。旅行の思い出や創造的なロケーションベースのビジュアルに最適です。

キャラクターの参照画像と選んだビジュアルスタイルを組み合わせて、特徴を保ちながら遊び心のある大きな頭のアバターを生成します。

複数の旅行写真を日本のジャーナル風の不規則なコラージュに変換し、インスタグラムや旅行ストーリーテリングに最適です。

適切なポーズ、衣装、白い背景で、清潔なパスポートスタイルのペットポートレートを生成します。ID、プロフィール、公式なペット写真に最適です。

メッセージアプリやコミュニティに最適な、様々な表情やポーズのアニメスタイルの絵文字セットを作成します。

写真をかわいいクレイスタイルのキャラクターに変換し、ポラロイドフレーム内に表示して遊び心のあるコレクティブルな美学を演出します。

ロゴの応用やブランド素材を含む、色とスタイルが一貫した完全なブランドビジュアルアイデンティティシステムを生成します。

服の要素を遊び心のあるシンボルやジャーナルスタイルのレイアウトで、クリエイティブなペーパーカットコラージュに変えて、ファッションのインスピレーションを得ましょう。

写真をレトロフューチャリスティックなスタイリング、遊び心のあるアクセサリー、2000年代初頭の象徴的な美学で大胆なY2K風ファッションビジュアルに変身させます。

キャラクターのオリジナルアートスタイルを保ちながら、別のキャラクターの衣装を着せることができます。ファンアートや創造的な変身に最適です。

本物の日本/韓国のセルフィー美学とシームレスなブレンドで、あなたとアイドルのインパクトのあるデュオセルフィーを生成します。

キャラクターを一人称視点で現実のロマンチックな日常シーンに配置し、没入感のあるストーリーテリングを実現します。
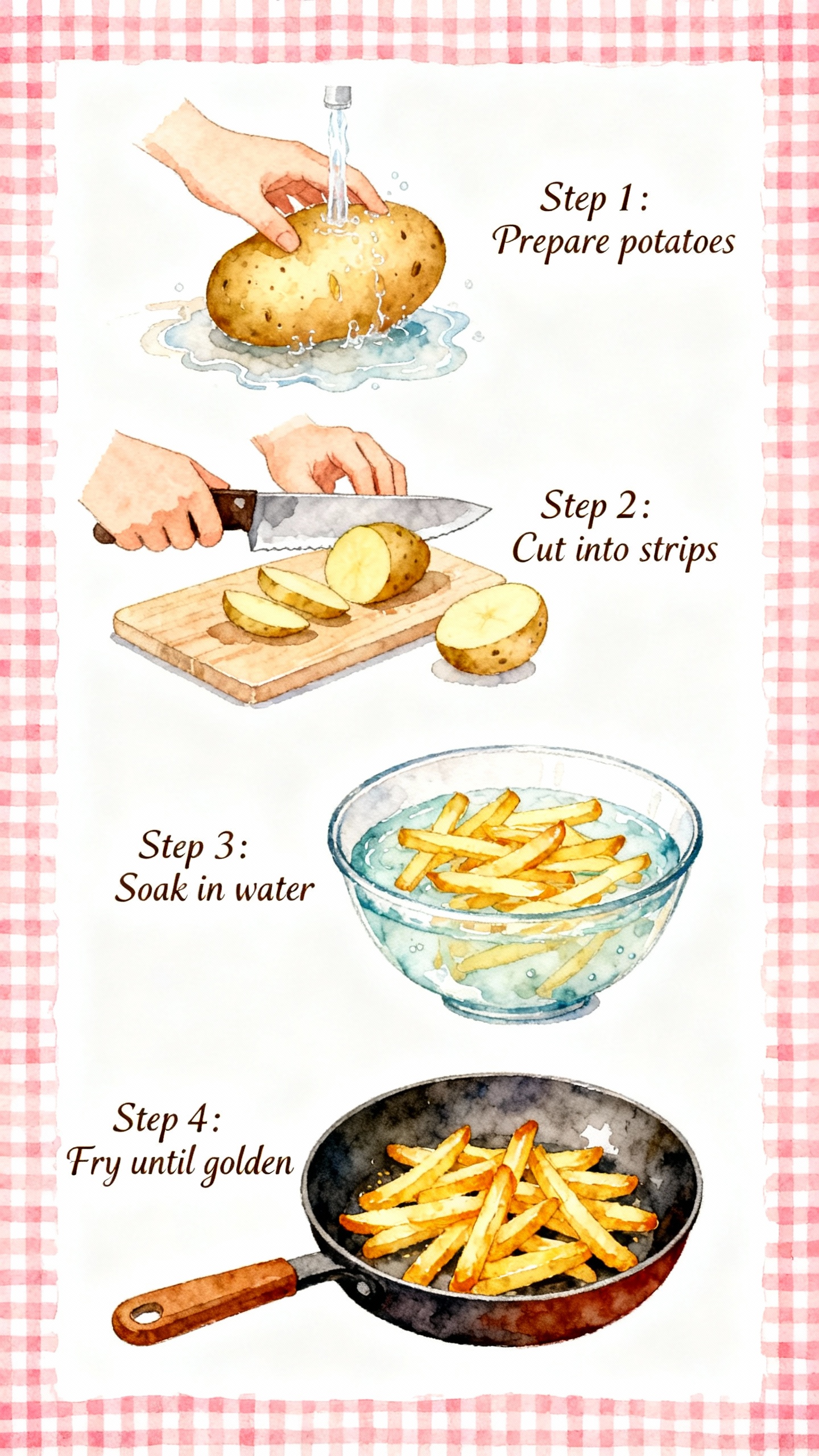
魅力的な日本風のレシピイラストを生成し、わかりやすいステップバイステップの料理手順と温かみのある癒しのビジュアルを提供します。

複数の角度からの完全な360度製品プレゼンテーションを生成し、詳細な製品検査に最適なクリーンなスタジオ照明を提供します。

製品を抽出し、構造化された比較レイアウトで提示し、主要な違いをクリーンなタイポグラフィと視覚的な明瞭さで強調します。

ブランドの一貫性と文化的関連性を維持しながら、異なる国や地域向けに製品プレゼンテーションをローカライズします。
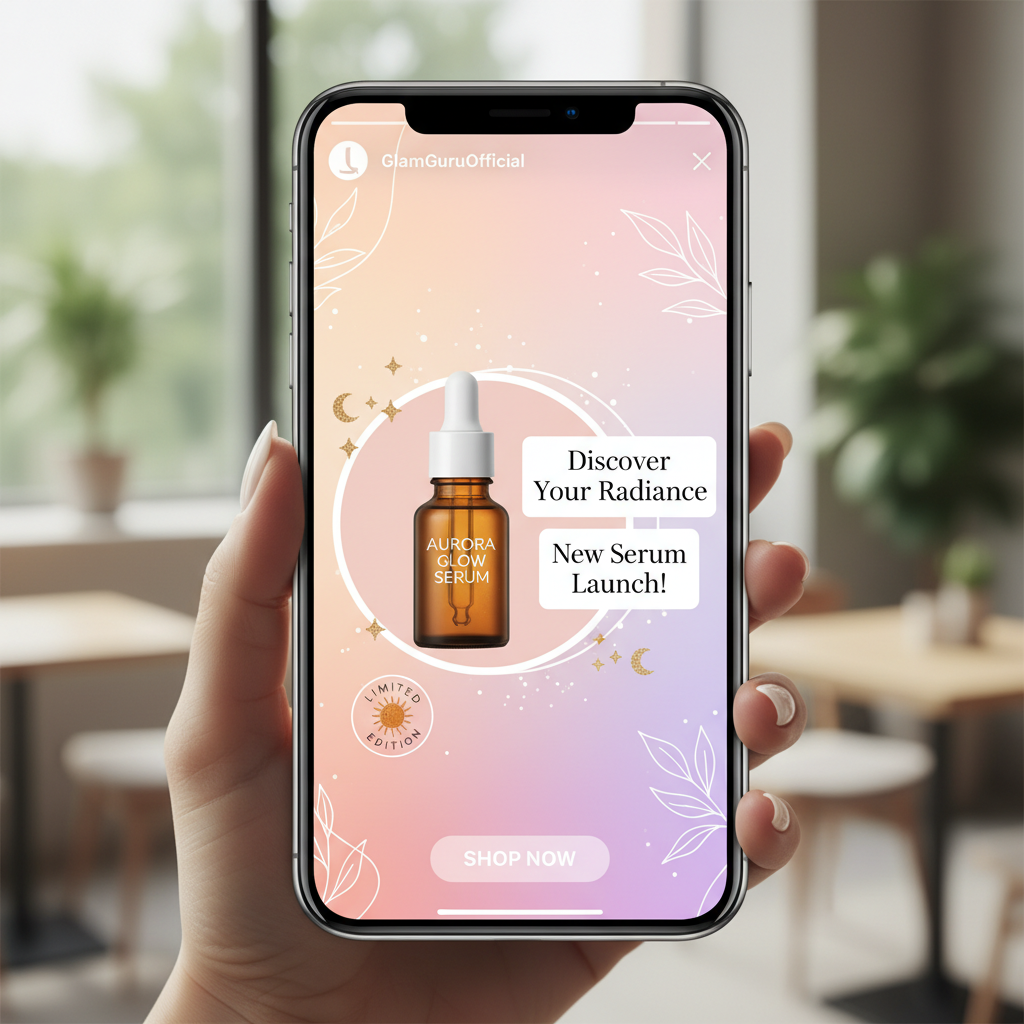
ソーシャルエンゲージメントに合わせたモダンなタイポグラフィ、色、レイアウトでInstagramストーリーのビジュアルをデザインします。

評価と推薦文を現代的なデザインで表示するレビューカードを作成し、社会的証明とマーケティングに活用します。

高級な環境でプロの照明を使用して、清潔で高品質な商品写真を生成します。これは、eコマースやマーケティングに最適です。

目を引くプロモーションバナーを作成し、太字のテキストと鮮やかなビジュアルで売上とコンバージョンを向上させましょう。

ビジネスやスタートアップに適した、ブランドスタイルと重要な要素を備えたユニークなロゴを作成します。
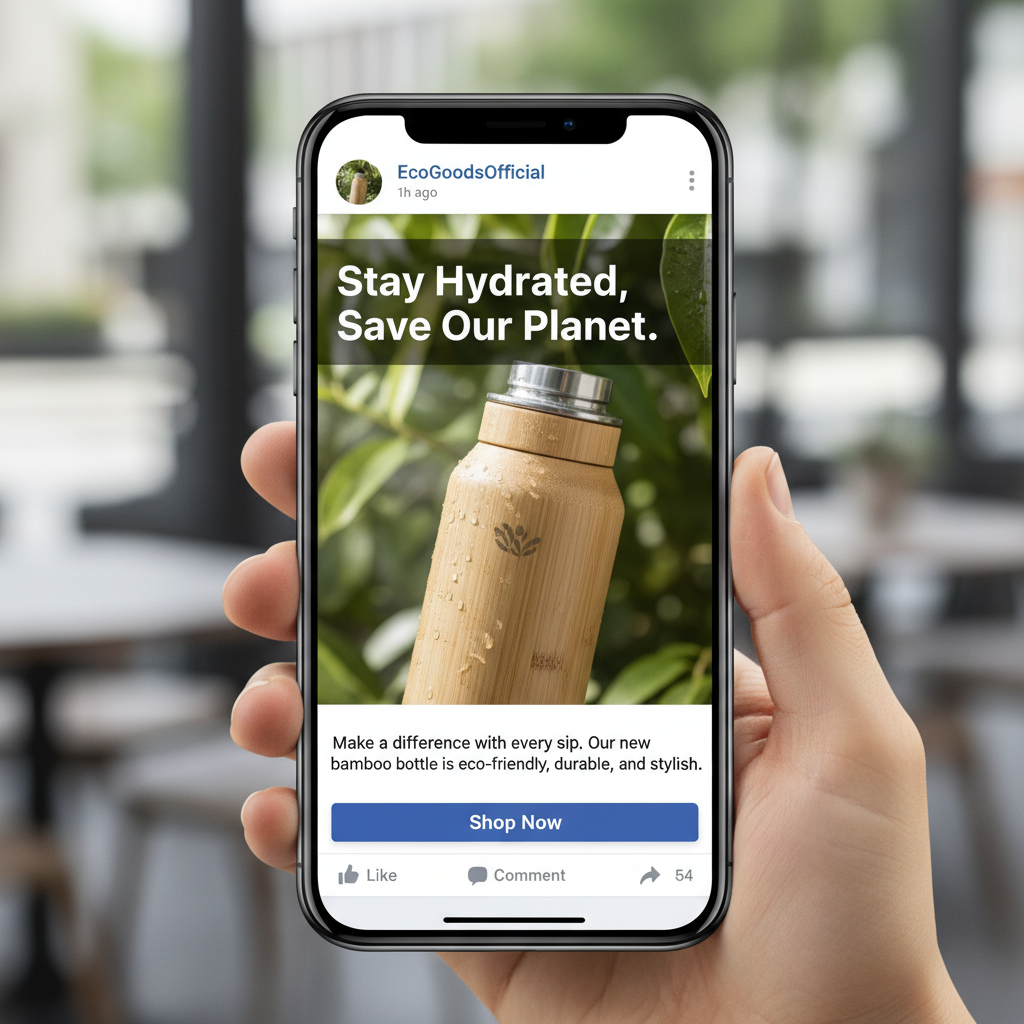
プロフェッショナルなビジュアルで、主要な利点を強調し、ターゲットオーディエンスに直接訴求するFacebook広告をデザインします。

ブランドロゴ、ハイライト、カラーテーマを用いた、店頭販売向けのパッケージデザインを作成します。

星座や性格タイプに基づいた色とシンボルを使って、性格テーマのイラストを生成します。

詳細な説明をもとに、人々、設定、感情を捉えた鮮やかなビジュアルシーンとして意味のある記憶を再現します。

夢の説明をシュールな視覚シーンに変換し、雰囲気と感情のトーンを捉えます。

プロのモデルが商品を持ち、正確なポーズ、照明、背景で商業スタイルの写真を生成します。

多様なモデルがスタジオやライフスタイルの設定で着用する衣類やアクセサリーを視覚化し、フィット感やスタイルをプレビューします。

写真を選んで、選んだキャラクターに合わせた衣装、メイク、背景で詳細なコスプレ変身を実現します。

照明や空を改善したり、気を散らすものを取り除いて、素晴らしい旅行の思い出を作りましょう。

写真を油絵、水彩画、スケッチなどのアート作品に変換し、創造的な表現を楽しみましょう。

リアルな天気エフェクトで画像を強化し、劇的で雰囲気のあるビジュアルを作成します。

リアルな反射とトレンディな部屋の設定で、SNS向けの写真を生成します。

ペットの写真をスタジオ照明と装飾的な背景でアーティスティックな肖像画に変身させ、記念品や共有に最適です。

美的フィルターと個性的な要素で、ソーシャルメディアプラットフォームに最適化されたスタイリッシュなアバターを生成します。

背景を完全に取り除き、メインの被写体をそのまま残します。商品画像、ポートレート、デザイン素材に最適です。

粒子とレトロなスタイルでクラシックなヴィンテージ効果を加え、写真にノスタルジックな雰囲気を与えます。

カスタムデザインやパターンを製品に適用し、コンセプトやブランディングを効果的に披露します。

顔の基本構造とアイデンティティを保ちながら性別スワップの変化を視覚化します。好奇心をそそる探求や創造的なポートレートに最適です。

リアルな配置とスタイリングで、デジタルにタトゥーを追加して体にデザインをプレビューします。

顔の外見を変えずに体型の変化をシミュレーションします。フィットネスや体格の目標を視覚化するのに最適です。

履歴書、LinkedIn、企業プロフィールに適した清潔でプロフェッショナルなビジネスプロフィール写真に変換します。

カスタマイズされたカラースキームで様々なインテリアスタイルの部屋を視覚化。ホームデコレーションのインスピレーションと計画に最適です。

エレガントなスタイリングとスタジオ照明でプロフェッショナルな家族写真を生成します。洗練されたビジュアルスタイルで、温かく調和のとれた家族の瞬間を完璧に捉えます。

統一されたキャラクター、環境背景、適切なポーズでテーマ別フォトアルバムを生成します。ストーリーテリング、文化的テーマ、ビジュアルコレクションに最適です。

プロの写真美学でロマンチックなウェディングスタイルのポートレートを作成します。結婚式の瞬間やカップルの思い出を視覚化するのに最適です。

美しい自然環境の中で、ペットと飼い主の深い絆を示す感動的で芸術的なシーンを生成します。

リアルな老化効果をシミュレートし、個人のアイデンティティを保ちながら、異なる人生段階での見た目を視覚化します。

シャープネス、明るさ、色のバランスを改善して、写真の品質を自動的に向上させます。鮮明さを取り戻し、写真をよりクリアで鮮やかに見せるのに最適です。

顔の構造を保ちながら、リアルなメイクをデジタルで施します。実際のメイクをする前にスタイルをプレビューするのに最適です。

柔らかい照明と親密な雰囲気の中で、2人が抱き合う感情的に暖かいシーンを生成します。ロマンチックで感傷的なビジュアルに最適です。

写真を情熱的なキスシーンに変え、映画のような照明と夢のような雰囲気を演出します。ロマンティックなストーリーテリングビジュアルに最適です。

古い家族写真の損傷を修復し、品質を向上させることで、大切な思い出を鮮明に蘇らせます。
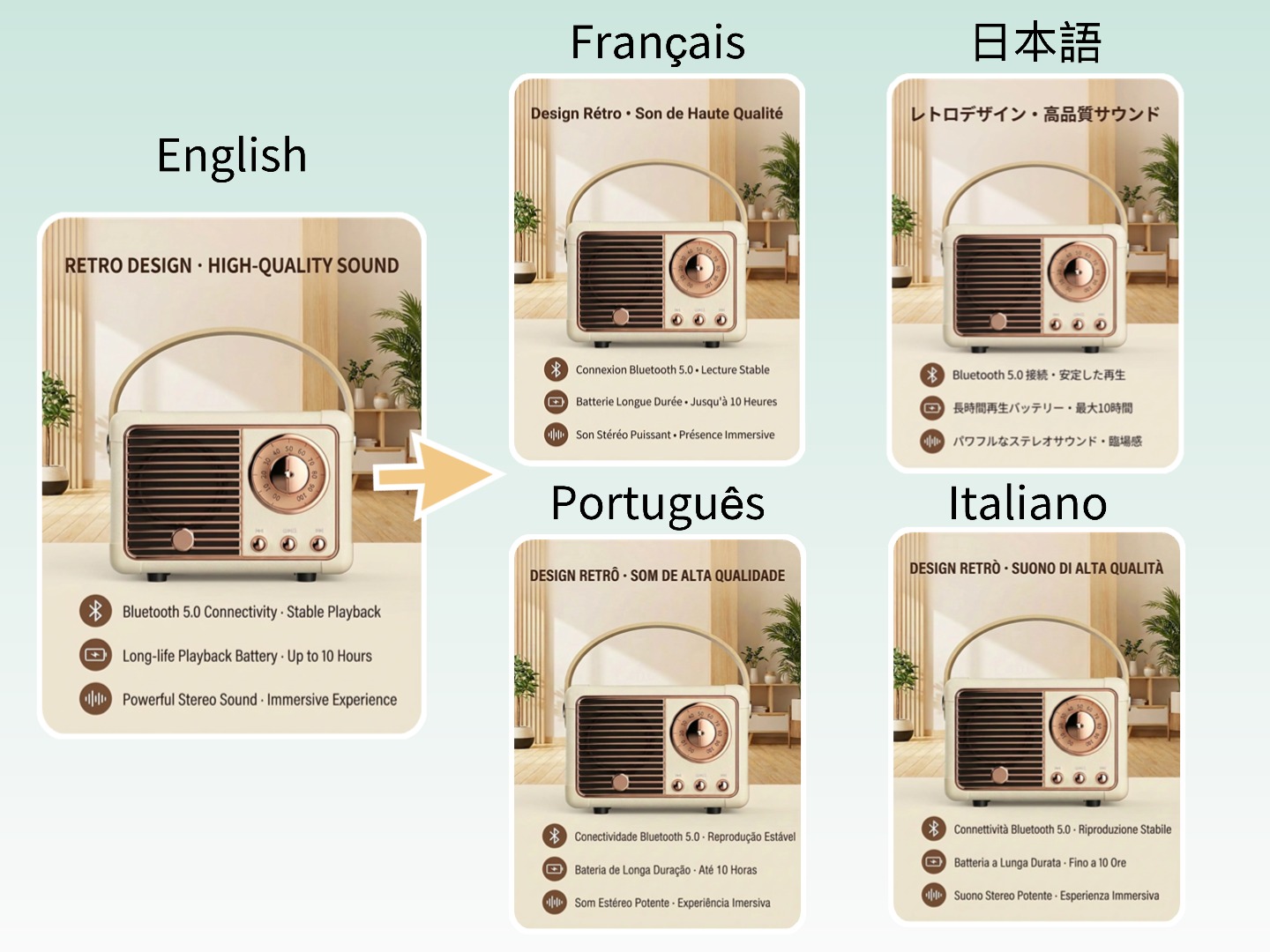
画像に埋め込まれたテキストを、元のレイアウト、タイポグラフィ、ビジュアルスタイル、構成を厳密に保ちながら、任意のターゲット言語に翻訳します。ポスター、UIスクリーンショット、広告、多言語ビジュアルコンテンツに最適です。

実際の写真をスタイライズされたデジタルアバターに変換し、顔の特徴や表情を保ちます。プロフィール画像、クリエイティブなポートレート、芸術的な変換に最適です。

顔や服装、照明をそのままにして、仮想的にヘアスタイルを変更します。本当に変える前にヘアカットをプレビューするのに最適です。

被写体をそのままに、写真の背景をシームレスに交換します。リアルな見た目のために、照明と影が自動調整されます。

ポーズや背景を変えずにデジタルで異なる衣装を試せます。ファッションプレビューやスタイリング実験に最適です。

Nano BiBiベビーフィルターであなたのポートレートをかわいい赤ちゃんバージョンに変身させましょう!ダウンロードやサインアップなしで、ハイパーリアルで楽しく安全な赤ちゃん変身をオンラインで楽しめます。

Nano BiBiティーンフィルターで高校生の自分を再発見!リアルで楽しく、安全なティーンエイジャーへの変身をオンラインで体験—ダウンロードやサインアップは不要です。

あなたのテーマをレゴ ミニフィギュアにして遊びの準備をしましょう。

あなたの画像を柔らかい手作りのかぎ針編み人形に変換します。Nano BiBiによって駆動され、Google Nano Bananaで生成されます。

Nano BiBiのHDエンハンスで写真をアップスケールして強化しましょう。Google Nano Bananaによって強化されたこのAI画像アップスケーラーは、シャープネス、鮮明さ、解像度を向上させます。写真の強化、ディテールの復元、高解像度のオンラインアップスケーリングに最適です。

Nano BiBiの背景変更を使って、あなたの写真の背景をクールでレトロなY2K美学に交換しましょう。Google Nano Bananaが提供するこのAI背景エディターは、シーンの置き換え、懐かしいY2Kの雰囲気を適用、またはトレンディな美学の変換を簡単に行えます。クリエイティブな編集、ソーシャルメディア、レトロスタイルの写真に最適です。

Google Nano Bananaが提供するNano BiBiのマーカースケッチで、あなたの写真を鮮やかなコピックマーカーのスケッチに再構築しましょう。このAIスケッチフィルターは、ポートレートやシーンをカラフルなマーカースタイルの絵に変換します。イラスト愛好家、デザインのインスピレーション、クリエイティブなアート効果に最適です。

どんな写真も、滑らかなストローク、正確な輪郭、変化に富んだ線の太さでプロフェッショナルな黒インクの線画に変換します。
オールインワンAIツール
Seedance 1.0は、ByteDanceの高品質なテキストからビデオ、画像からビデオへのモデルで、滑らかで安定した動き、強力なプロンプトフォロー、ネイティブなマルチショットストーリーテリングに焦点を当てています。Proは最大1080pの出力を対象としています。
Veo 3 Fastは、Googleの次世代AIビデオ生成モデルで、スピードと効率に最適化されています。ユーザーはテキストや画像のプロンプトから直接、音声(対話、環境音効果、背景音楽を含む)と同期した短いシネマティッククリップ(通常8秒まで)を作成できます。迅速な反復を目的としたVeo 3 Fastは、高品質な出力を低コストで短時間で提供し、AIビデオコンテンツの迅速な作成を求めるクリエイター、マーケター、開発者に最適です。
Hailuo-02は、MiniMaxの次世代マルチモーダルビデオ生成モデルであり、テキストプロンプトや静止画像を短く高精細なシネマティッククリップに変換することができます。ネイティブ1080p出力、リアルな物理シミュレーション、精密な動作制御をサポートしており、アクション、ストーリーテリング、クリエイティブなビジュアルコンテンツに適しています。Hailuo-02は、AIビデオ作成の分野でGoogleのVeoシリーズのようなモデルと競合することを目指しています。
Veo 3は、Googleの最先端の生成ビデオモデルであり、テキストまたはビジュアルプロンプトから同期されたオーディオ(対話、環境音、音楽、効果音)を伴った短く高精細なビデオクリップを生成することができます。これは、画像と映画の間のギャップを埋め、高度な視覚的リアリズム、物理学の理解、シームレスな音の統合を組み合わせたものです。すべてがアクセスしやすいAPIとクリエイティブな環境内で実現されています。
オールインワンAIツール
スピーチ-02 HDは、MiniMaxのフラッグシップテキスト読み上げ(TTS)モデルで、ナレーションやオーディオブック、声優などのプレミアムオーディオ用途に最適化されています。短い参照音声から話者をクローンするゼロショット音声クローン、感情表現、豊富な多言語サポート、音声属性の細かい制御をサポートしています。このモデルは、新しいFlow-VAEと学習可能な話者エンコーダーを活用して、文字起こしを必要とせずに音色の特徴を抽出します。
表現力豊かで自然な音声を生成します。ユニークな感情コントロール、短い音声からの即時ボイスクローン、組み込みの透かし機能を備えています。
音声合成、感情表現、多言語対応を提供するテキストからオーディオ(T2A)システム。低遅延でリアルタイムアプリケーション向けに設計されています。
オールインワンAIツール

AIで写真を簡単にクリーンアップ。 強力なAIオブジェクト除去ツールを使えば、不要な人、テキスト、ロゴ、背景の雑音を数秒で消去できます。Photoshopのスキルは不要です。 画像をアップロードし、削除したい部分をハイライトするだけで、AIが自然に背景を埋めてくれます。
AIインペイントを使用して写真を精密に変換します。 AIインペイントツールを使用すると、マスク画像に基づいて選択した領域を塗りつぶしたり置換したりして、画像の任意の部分をインテリジェントに修正できます。 損傷した部分の修復、背景の置換、新しいコンテンツの生成など、AIは周囲のピクセルとシームレスにブレンドし、自然でリアルな外観を実現します。
画像を元の境界を超えて簡単に拡張できます。 AIアウトペイントツールは、既存の画像と完璧に調和する新しいビジュアルコンテンツをインテリジェントに生成し、左、右、上、下の空きスペースを目立たないように埋めます。 ワイドスクリーンビジュアルの作成、トリミングされたエリアの復元、ソーシャルメディアやクリエイティブプロジェクトのための構図の強化に最適です。
自然言語を使って写真を賢く編集。 AI検索&置換ツールは、見つけたいものと置換したいものを記述するだけで、手動のマスキングは不要です。AIに変更したいオブジェクトを伝えるだけで、自動的に検出、セグメント化し、希望のコンテンツに置換します。照明、影、視点を保ちながら。
自然言語を使用して、画像内の特定のオブジェクトの色を変換します。検索とリカラーサービスは、「シャツ」「車」「ソファ」など、あなたが説明するオブジェクトをインテリジェントに検出し、手動でのマスキングなしで自動的に色を変更します。eコマース、デザイン、クリエイティブ編集に最適です。
AIの精度で画像の背景を簡単に除去または置換。 背景除去サービスは、画像内の被写体を賢く検出し、背景から分離して、清潔で透明またはカスタムの背景を生成します。商品写真、プロフィール写真、クリエイティブデザインに最適です。
Stability AIの拡散モデルの最先端を体験しよう。 Stable Diffusion 3.5は、比類なき画像品質、プロンプトの正確性、そして複数のモデル層にわたる生成速度を融合しています。LargeからFlashまで、クリエイター、アーティスト、開発者向けに設計されたSD 3.5は、細やかな制御、創造的な柔軟性、最先端のパフォーマンスでプロフェッショナルな結果を提供します。

AIで瞬時に画像を強化。 高速アップスケーラーは、先進的な予測および生成AIを使用して画像解像度を4倍に向上させます — すべて約1秒で。 軽量で効率的、日常使用に最適化された高速アップスケーラーは、圧縮された低品質の画像に鮮明さと詳細を復元し、ソーシャルメディア投稿やデジタルコンテンツ、迅速なビジュアル強化に最適です。
すべてのディテールを保ちながら、よりシャープで大きく、クリーンに。 保守的なアップスケーラーサービスは、64×64ピクセルから1メガピクセルまでの画像をフル4K解像度(最大40倍のアップスケール)に拡大し、元の特徴、色、スタイルをすべて維持します。 生成モデルがコンテンツを「再構築」するのとは異なり、保守的なアップスケールは本物の復元に焦点を当て、画像がまったく同じままで、よりクリアで高解像度になることを保証します。

ナノ バナナは次世代の画像生成・編集モデルで、テキストプロンプトと画像入力を組み合わせて、驚異的な忠実度でビジュアルを作成または変換します。複数画像の融合、キャラクターの一貫性、ターゲット編集、アウトペインティングとインペインティングをサポートし、すべて自然言語コマンドで駆動されます。ジェミニエコシステムを通じて展開され、クリエイター、ブランド、開発者向けにプロフェッショナルな画像ワークフローを提供します。

Gemini 3 Pro Imageは、プロフェッショナル品質のAIによる画像生成と編集を提供します。1K/2K/4Kの解像度、鮮明なテキストレンダリング、リアルタイムデータの基盤、最大14枚の参照画像のサポートを備え、マーケティング資産、インフォグラフィック、コンセプトアート、UI/UXモックアップなどに最適です。
スケッチを瞬時に洗練されたビジュアルに変換します。 スケッチサービスは、デザイナー、アーティスト、クリエイター向けに設計されており、迅速なアイデア出しと反復作業をサポートします。手描きのラフなコンセプトを洗練された詳細な画像に変換し、構造を維持しながら明瞭さ、スタイル、視覚的魅力を向上させます。 スケッチ以外の画像に対しても、輪郭やエッジを正確に制御し、形状、質感、照明の詳細な調整を可能にし、元のデザイン意図を損なうことなく仕上げます。
構造の完全性を保ちながら再現し、再構築します。 ストラクチャーサービスは、入力画像の構成、幾何学、空間レイアウトを保ちながら新しい画像を生成します。シーンの再現、環境デザイン、キャラクターのレンダリングなど、ポーズ、フレーミング、構造を一貫して保つ必要がある高度なコンテンツ作成シナリオに最適です。 アーティスト、開発者、スタジオが創造的なバリエーションや制作パイプライン全体で正確な視覚的コントロールを必要とする場合に理想的です。

AIの精度で任意の画像の外観と雰囲気を再現します。 スタイルガイドサービスは、コントロール画像からカラーパレット、筆使い、照明、トーンなどのスタイル要素を抽出し、そのスタイルをテキストプロンプトから生成された新しい画像に適用します。 結果は、選択した参照の芸術的なムード、色の調和、美的構造を反映した視覚的に一貫した出力です。 ブランドビジュアル、アートシリーズ、または複数プロジェクトにわたるクリエイティブな方向性を維持するのに最適です。

選んだスタイルで画像を再構築し、構造とレイアウトをそのままに。 スタイル転送サービスは、1つまたは複数の参照スタイル画像から視覚的な特徴をターゲット画像に適用し、元のコンテンツの構図、視点、幾何学を保持します。 スタイルガイドとは異なり、スタイル転送は既存のビジュアルを変換します。デザインシステム、製品画像、ブランドキャンペーンで一貫した美学を維持するのに最適です。

精密切り抜きは、ピクセルレベルの精度で画像の背景を除去します。サイズ制限なし、圧縮なし。プロフェッショナル向けに設計されており、超高解像度画像や髪の毛や透明素材のような複雑なエッジを処理し、被写体の完全性を維持します。

自分の参照画像を使用して、超リアルなクリスマス写真撮影のポートレートを作成します。顔の特徴、肌の質感、自然なディテールをプロのスタジオ照明、浅い被写界深度、そしてクリスマスの華やかな美学で保ちます。インフルエンサー、ソーシャルメディア、個人のブランディングに最適です。

被写体のアイデンティティを保ちながら、参照画像を使用してプロフェッショナルで超リアルなポートレートを生成します。このプロンプトは、正確な顔の特徴、自然な肌の質感、本物のライティングを保証しつつ、ポーズ、表情、衣装、環境の柔軟なコントロールを可能にします。インフルエンサーのポートレート、編集写真、パーソナルブランディング、高級AIフォトシュートに最適です。

特定の国の結婚文化と美学に基づいた超リアルなウェディングドレスのポートレートを生成します。アイデンティティを保ちながら、ブライダルスタイル、ロケーション、時間帯、各国に合わせたプロフェッショナルな写真撮影の詳細をカスタマイズするために、参考画像をアップロードしてください。
自然でリアルな印象を保ちながら、外見を洗練する微妙な美しさの向上でポートレートの質を高めます。